Abstract
As a part of the Intelligent Systems course that constituted towards my undergraduate degree I was tasked with the creation of a machine learning model using one of the many techniques that are commonly encountered in the field of Artificial Intelligence. This project explores the development of a supervised image classifier using a convolutional neural network. Making use of the PyTorch library, it focuses on breaking down the constituent parts of an image classifier to provide an in-depth analysis of the intricacies of the architecture, training process, and performance evaluation, while utilising CUDA acceleration along the way to speed up the model processes. After a meticulous process of iterative refinement and the addition of data augmentation techniques, the resulting custom CNN architecture achieved an accuracy score of 85.21% on the “Animal Species Classification - V3” dataset from Kaggle, a respectable result that aptly demonstrates the potential that CNNs hold for image classification tasks. Additionally, suggestions for future improvements are explored, including the implementation of transfer learning and the inclusion of new metrics, paving the way for future iterations of the model to produce greater, more accurate results.
Introduction
In the field of artificial intelligence, computer vision has been a long-standing point of interest for many professionals in various fields. The ability for machines to automate tasks previously only capable by humans has led to great advancements across a myriad of industries, from the security sector where AI has been implemented for real-time movement detection, to medicine where computer vision has been trained to recognise medical imagery such as X-Rays and CT-scans to diagnose patients with speed and accuracy, providing a potentially lifesaving second opinion to medical professionals. With the applications of computer vision being so vast, it becomes a necessity to divide the field into various subsets, each taking a unique direction to solve the problem at hand. One such subset is image classification which involves training an AI model to assign a label or category to an image based on its content or features. This area will be the focus of this project, a deep dive into the different methods used to create image classification systems will be conducted to collect the necessary information required to create a sophisticated model that can achieve strong results in performance metrics such as accuracy, generalisation, and speed.
Aims and Objectives
The first and primary objective of this project is to produce a model that can demonstrate satisfactory accuracy metrics when presented with previously unseen data. Through the exploration of the various factors that contribute to a successful machine learning model, the aim is to accumulate the knowledge gained to make astute design decisions that will help contribute to the performance goals expected of the final product. As a subset of this aim, the model will also be expected to display a high level of robustness and generalisation across its testing; variations in lighting, angle, orientation, and background should in no way compromise the performance of the model to ensure that the model has real-world viability.
Further goals pursued by this project include scalability and efficiency. All stages of the process should be able to efficiently utilise the hardware resources at its disposal to make every facet of the model faster and less computationally expensive, allowing the resources saved through optimisation to be reinvested in more productive ways such as increasing the model complexity or expanding the quantity of training data to improve accuracy metrics. Furthermore, efficient utilisation of the hardware creates the potential for the model to make predictions at a faster rate, potentially opening up the opportunity for real-time performance.
The final objective for this project was a transparent display of performance metrics. To foster a strong understanding of model progression and performance, the implementation of ongoing statistics would provide an efficient way of comparing and contrasting the model at multiple points along its progression, which could then be used to assess model performance and integrate operations such as early stopping, where a model’s training is halted before the pre-programmed number of epochs to prevent overfitting. This project will also seek to implement the collected data in a more visually digestible manner through the creation of graphs and other visualisations to shed light on the trends and patterns that would not have been immediately obvious from the raw data alone.
Method
With the focus of this project being on the creation of a supervised image classifier, a prerequisite step before the development of the machine learner could begin was the selection of an appropriate dataset to build the model around. With the dataset being the cornerstone from which the model’s understanding is built, it was handled with careful consideration as it was recognised that failure in picking a suitable dataset would almost certainly compromise the overall performance of the model, jeopardising the project’s primary objective. With this in mind, there were a few fundamental factors that were outlined during the selection process, the first of which was the need for quality. For an image classifier, this involved the training images being sharp, well-lit, and of an acceptable resolution to ensure that distinctive features are clear and discernible to aid in the identification of key patterns that are essential to the image classification process.
The other important factor that needed to be considered during the dataset selection process was the quantity of the data. Intuitively, the more information the model has to learn from, the more effectively it is going to be able to identify and classify similar data in unknown contexts. For this reason, each classification label should ideally contain a few thousand associated images for optimal training. However, to avoid biases within the model that could cause compromises to model accuracy, it is also crucial that the quantity of the data is balanced across the different classes as while methods do exist for the artificial balancing of datasets, native balance remains the most desirable choice and subsequently was a sought-after feature in the selection process.
With all of these factors considered, the “Animal Species Classification - V3” dataset was sourced from the popular machine-learning website Kaggle for use in this project. The 256x256 image resolution provided plenty of image detail for feature recognition while the sizable amount of data, totalling 2000 images per class, ensured that the model had a plentiful amount of balanced data to achieve strong results in testing. Furthermore, the inclusion of 15 distinct image categories enhanced the potential for comprehensive model exploration and evaluation, as the increased complexity and variability presented a harder challenge that required a more complex and fine-tuned model to generate good results.
The language selection for the project was a fairly simple affair as Python has shown itself to be the de facto choice for artificial intelligence applications, with various libraries and frameworks tailor-made for machine learning being actively used in professional applications, making it a natural fit for this project. Choosing between these libraries, however, is a slightly more nuanced task with each framework touting its strengths that make the selection process highly dependent on the task at hand. For the deep learning approach that this project looks to pursue, there are two clear front-running libraries to choose from, Keras and PyTorch. This choice was relatively inconsequential as both of these libraries provide all the functionality required for this project. However, in recent years PyTorch has established itself as the more popular choice of the two through its speed, intuitiveness and flexibility, which gave it the edge over Keras for this project.
Loading the different sections dataset into a useful format for machine learning was a two-step process, handled by a combination of the ‘ImageFolder’ class and ‘DataLoader’ class included in PyTorch. The ‘ImageFolder’ class managed the assignment of the relevant labels to the images as they were loaded, using the folder structure of the dataset as the reference for doing so. Additionally, it offered the ability to apply transformations to the images on the fly such as image resizing and tensor conversion which were both essential pre-processing steps for CNN compatibility. Once the dataset had been correctly formatted and transformed, the ‘DataLoader’ class was introduced to enable batch loading, shuffling, and parallel data loading capabilities which facilitated a decrease in training time and an improvement in model generalisation.
Establishing the architecture for the training of the model required the assignment of a loss function to measure how close the model’s prediction was to the ground truth and an optimiser that could use the value generated by the loss function to backpropagate the weights of the model, facilitating the learning process. Cross-entropy loss was the natural selection for the loss function as its ability to measure the discrepancy between class probabilities and the true value aligns it perfectly with the objective of a classifier which aims to make predictions that match the ground truth value as closely as possible. For the optimiser, it was the ‘Adam’ optimiser that was selected; as a variation of the ever-popular Stochastic Gradient Descent (SGD) optimiser, ‘Adam’ shares many of the same advantages as SGD while also providing variable learning rate functionality that can assist in hastening model convergence. While this does come at the cost of extra performance overhead, it was deemed a worthwhile trade-off for this application. The final addition to the training architecture was a gradient scaler to manage the normalisation of the input data. To maximise the effectiveness of the hardware available, the CUDA AMP scaler was selected for its ability to utilise GPU architecture to dynamically convert parts of the network to half precision where full precision wouldn’t be necessary, speeding up computation time without sacrificing anything in the way of accuracy, making it an astute choice to reduce the lengthy training times that often accompany CNNs.
To reliably test the real-world performance of the model, a separate testing procedure needed to be configured that omitted any form of backpropagation when making predictions. The nature of CNNs allows them to memorise the underlying patterns of the training data, a process which forms the basis for classification. However, during the training process, the model will begin to gradually memorise the input data rather than learn the underlying features, a phenomenon known as overfitting. This leads to inflated training accuracy scores that are not indicative of the model’s real-world performance and as such cannot be used as a reliable metric for assessing model performance. By disabling backpropagation when making predictions on the validation and testing subsets of the data, the model is prevented from learning features from the input image, allowing the data to remain ‘unseen’ over multiple iterations of testing, ensuring their continual value in assessing the model’s true performance.
With all the necessary structures in place, the focus could be turned to creating and fine-tuning the model itself. The model made use of five different types of layers, starting with convolutional layers that act as the backbone of the CNN. These layers apply a sliding filter over the image and by computing the dot product between the model’s weights and the values of the current region, the layer can extract model features to build up a representation of the labelled class. Following the convolutional layers, rectified linear units were added to provide non-linearity to the layers, enabling each of the subsequent convolutional layers to build upon each other to capture more complex features and patterns in the data. Batch normalisation layers were then introduced to standardise the inputs into each layer, improving convergence speeds and overall model stability which was vital as the model increased in complexity. Dropout layers were also added to help improve model resilience by randomly omitting neurons during training, ensuring that the model never became overly reliant on any single neuron. The final layers of the model were the fully connected layers. These layers were responsible for connecting all of the neurons from each convolution layer together to form a one-dimensional output from which predictions could be made.
Finding the optimal combination of layers for the model architecture was a process of trial and error. The model was steadily built up over many iterations of training, starting with just the fundamental three layers of the convolution layer, the rectified linear unit, and the fully connected layer, with depth gradually being increased until a plateau in performance was reached. At this point, the batch normalisation and dropout layers were introduced to overcome the stagnation and through further iterations, the final model architecture was reached. With an architecture established, the focus could then be transitioned to tuning hyper-parameters such as batch size and learning rate. This process shared many similarities with the creation of the model architecture, requiring an iterative approach to determine what values corresponded to the greatest levels of accuracy to create a resulting model that was well suited to its target domain.
 Figure 1 - Final Model Architecture
Figure 1 - Final Model Architecture
To evaluate the model the performance of the model, a couple of key metrics were measured, the first of which was the model loss. This value was measured to quantify the disparity between the model’s prediction and the target values, providing insight into how the model is responding to training. The other metric measured was percentage accuracy, this statistic provides a direct measure of how effective the model is at correctly classifying images and is of particular use for comparing model performance against other, similar solutions to provide context for the accuracy numbers. As intended, both metrics also played a role in influencing the early-stop mechanism. After each epoch, both validation loss and validation accuracy were tested for progression to ensure only the most performant version of the model was saved and once all forms of progression had stagnated for five epochs further training was halted to prevent any unnecessary computation.
Results and Discussion
When trained on the initial dataset, forgoing any augmented data, validation accuracy and validation loss reached their most promising values at the same time on epoch 37, with the resulting model demonstrating an accuracy score of 79.37% when evaluated on the test set. Each epoch took approximately two minutes to complete when performed on an RTX 3070 GPU, resulting in convergence being found after 1 hour and 50 minutes and the early stopping mechanism terminating any further training after 2 hours and 6 minutes on epoch 43.
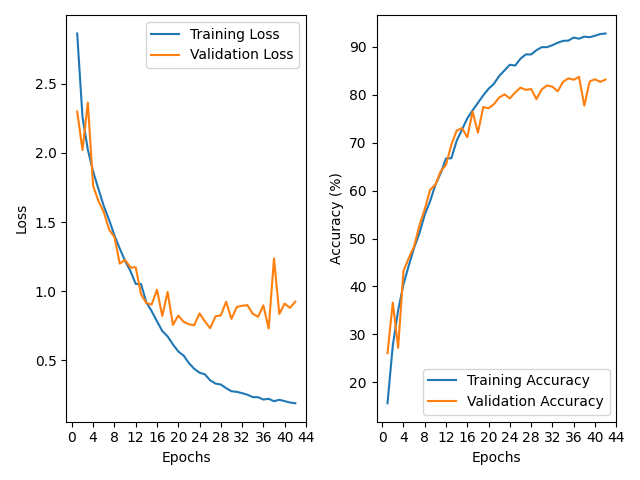 Figure 2 - Base Data Results
Figure 2 - Base Data Results
Adding the included pre-generated augmented images, totalling 10000 per class, to the training set, notable performance improvements were observed; the model seeking the highest validation accuracy demonstrated a testing accuracy of 84.59% after 22 epochs, while the model seeking the lowest validation loss value reached an accuracy of 85.21% after 11 epochs, an improvement ranging from 5.22% to 5.84% over the results from the base data. While the augmented models converged in significantly fewer epochs, the actual training time of the model was significantly longer as each epoch took around 20 minutes to complete, resulting in a training time ranging from 4 hours for the minimum loss model, to 7 hours and 20 minutes for the model measured on maximum validation set accuracy.
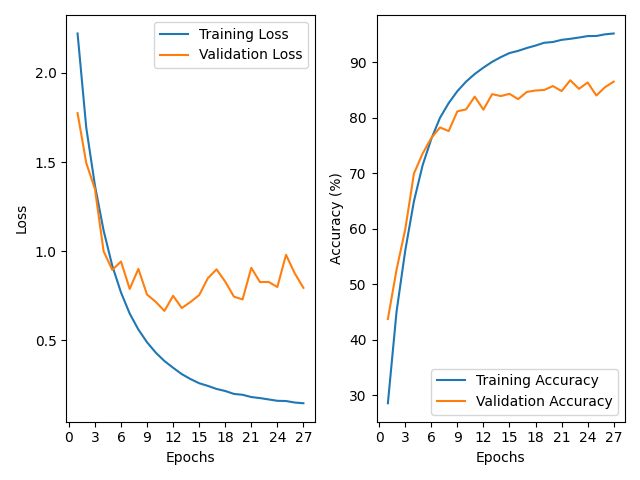 Figure 3- Augmented Data Results
Figure 3- Augmented Data Results
Overall, a peak accuracy of 85.21% is a satisfactory result that shows the competence of this custom CNN architecture for animal classification purposes. However, this result also leaves plenty of headroom for future improvement, as demonstrated by other attempts at classification using this dataset that have boasted over 95% accuracy scores by leveraging the domain knowledge of popular pre-trained models such as VGG and ResNet which were initially trained on much larger and diverse datasets such as ImageNet. Illustrating the effectiveness that transfer learning possesses in image classification applications.
As the model grew in complexity, the sizable training time proved to be a significant bottleneck in fine-tuning efforts. The multi-hour training times heavily impacted the ability to experiment with different hyperparameters, with overall development being limited to the use of the initial dataset alone as any form of meaningful development became entirely infeasible once the augmented data was introduced, limiting the involvement of this data to the final model run once all parameters had been settled on to provide a final boost in accuracy. Going forward, an investment in cloud computing or additional, more powerful hardware would need to be explored to alleviate training times and provide the headroom required for the development of more complex models that could boost accuracy beyond its current limit.
The final test performed on the model was the calculation of the inference time to determine how suitable the model would be for real-time computing applications. These tests revealed that the model could produce a prediction in approximately 0.2 seconds, equivalent to five frames per second. While this is a respectably fast inference speed, it falls short of true real-time performance for which the benchmark is 0.04 seconds, the equivalent of 24 frames per second. Despite this, the model performs at a fast enough speed to where it would remain a suitable candidate for applications where fast-paced inference is a requirement.
Conclusion
The project’s final accuracy score of 85.21% represented a strong result that mostly fulfilled the initial goal presented of producing an image classifier that was capable of effective animal classification. To boost accuracy further, inspiration would be drawn from the highest-performing classifiers of this dataset by exploring the use of transfer learning techniques to apply domain knowledge from other datasets to the task at hand. The second objective of maximising resource utilisation was also largely achieved, with CUDA acceleration significantly reducing processing times across multiple aspects of the project. This enabled the construction of a substantially deeper model compared to one relying solely on CPU resources, undoubtedly contributing to the final performance of the model.
The final objective of the study, the transparent display of metrics, highlighted both areas of success and places of potential improvement. The two metrics measured were highly influential across many facets of the project and the generated graphs proved to be an important asset in the assessment of the model. However, improvements such as the inclusion of supplementary metrics, like F1 precision and recall, could provide an even clearer view of model behaviour, while the introduction of live graphing would provide real-time insights into data trends that would be an invaluable addition to the project.
As a whole, this project provided a comprehensive view of the inner workings of CNNs and machine learning. Key lessons were learned about the processes that contribute to the creation of a successful deep-learning classifier, from the nuances of the supporting structures to the crucial role that data quality and quantity play in achieving a successful result. Moreover, the decision to pursue a custom model architecture over the integration of a pre-designed architecture provided an insightful look into the role each of the layers plays in the development of a successful image classifier, making the entire process a highly educational experience.